Deployment Schedules

Whenever I saw a message on the #emergency Slack channel, I used to have a mini-panic attack.
Did one of my teams release something that broke the service?
Anything on the emergency channel was visible to all stakeholders, so we had to immediately jump on the alert and triage. My team was in-charge of a revenue critical service, whose downtime could mean a non-trivial revenue loss. And unfortunately, our services used to go down fairly frequently. So, I was always on high-alert.
If it ended up being our service:
- we had to triage it (no one knew who specifically)
- we had to fix it (what if that person is not available?)
- we had to release it (again who?)
With over 20 people in charge of the service, we baldy needed an improvement to our processes.
Current Processes
Two things our org did well:
- We were only allowed to deploy between 9am-3pm M-T. We needed to get approval for after-hours deploys, but nothing actually prevented the deploy itself from running. Some issues were later noted during post mortem to have occurred due to after-hour deploys.
- We had a strict roll-back-first policy if something goes wrong in production. So our services had to have been setup to handle this appropriately (database migration downgrade is written when deploying a new version to production, for example)
Each team had their own deployment processes and we used to follow on-demand deploys. When the tech lead feels like there are enough tickets, there is a hotfix or a new feature, they may choose to deploy it anytime during the day.
Testing was done by another team, but they were swamped with work so there was no approval process. We may push something to production before we get the testing team or the product manager's approval (!!).
Inspiration
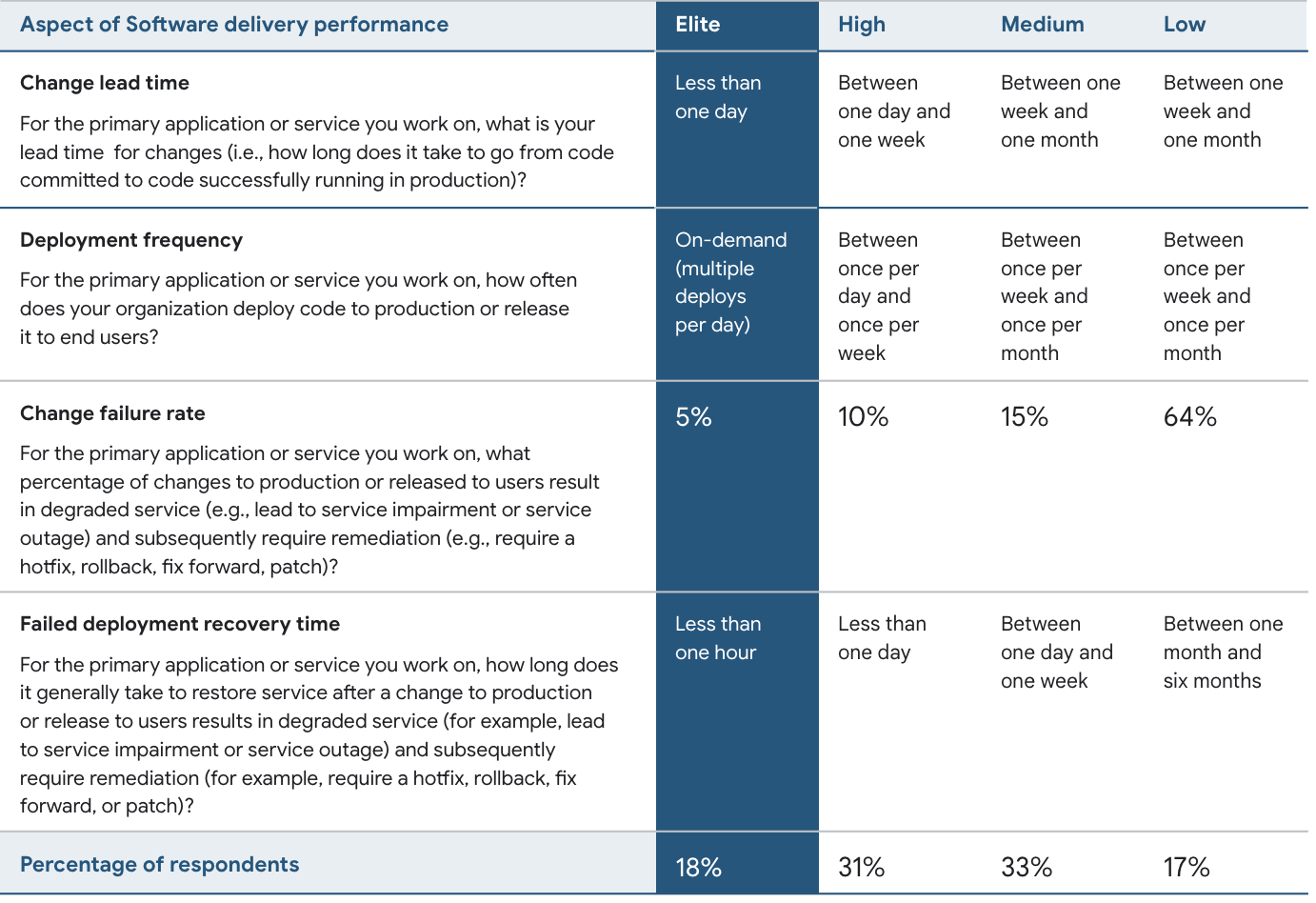
According to Google's report, a team should ideally be in the Elite column for all aspects. We were in principle "Elite" for Deployment frequency, but that impacted our Change failure rate and Time to restore service. We needed to take a step back and rethink our strategy.
Bespoke Release Management
Each team may have their own requirements and SLOs to adhere to, so instead of focusing on org-wide changes, I focused on how we can ensure we are pushing out high quality and reliable code. There are several aspects to improving the reliability of an application but this post will talk specifically about the release management process.
Release Management Pair
First, we wanted to distribute the role of releases to ALL the engineers of the team. All the engineers were paired up based on their experience and were assigned a week in rotation. Pair transitions happened on Tuesday EOD (after minor release day) so that the context of the week remains with the same release pair until the service is in production.
This strategy sounds counter-intuitive and people were skeptical. But my take was this - release engineers get a first hand view of:
- how their PRs directly impact releases
- what other teams are working on
- what are the issues that plague production, and how the code written by them/others cause this
This turned out to be a fantastic decision. All the engineers started taking more ownership in the combined success of the service and actively started having discussions around how to reduce the chance of our service going down.
Primary
Primaries were the senior engineers on the team.
- Tracking PRs ready for release
- Cutting release and deploy to stage
- Coordinate with secondary to monitor deployment
- Notifying release manager when ready for production deployment
- After confirmation, deploy to production
Secondary
Secondaries were usually the more junior engineers. By shadowing a senior engineer, they get to learn while still playing an important role in the stability of the service
- Monitoring slack channels
- Reporting bugs on respective Jira boards
- Confirm if appropriate monitors/alerts have been setup. Adjust if too noisy
Manager
This role was either played by the tech lead, engineering manager or me as the director.
- On deploy days, managers will be on call with Primary and Secondary to walk through deployment
- Run through the deployment checklist
- Get PO sign off
Schedule
Doubling down on the org-wide mandate, we made sure no deployment happen after the cut-off time, 3PM. Any urgent deployments/fixes will need approvals from the product manager, engineering director and Devops.
In addition to that, we created 3 release days:
Minor Releases
Major (and if no major PRs, minor) releases will be done on Tuesdays 10am. They could be significant changes like optimizations, minor refactors but are not breaking changes. Major release essentially mean a minor semver version bump.
Tuesday gives the team almost 4 working days to monitor the service and roll back if needed.
Patch Releases
Minor releases will be done on Thursdays 10am. They can be minor fixes, logging, more observability code, tests etc.
Minor releases are the semver patch releases.
Major Architecture Changes or New Feature Releases
These releases were more involved and may even need multiple other teams on calls to coordinate. These were scheduled separately (again, either on Monday or Tuesday to give us time to monitor and roll back).
While there is no hard and fast rule, observation had shown that major release happen 2-4x a year, minor releases happen 2-4x a month, and patch releases very often
Release call
At 10am on release days, we have a call with all the representatives present - product manager whose PR is being released, testing engineer, release management pair, myself and any engineer whose PR is being released. We took these calls seriously and had to run through a checklist before the deploy.
The release management pair committed to pushing a release candidate to stage atleast 24 hours before a major release day. That gives the PMs and test engineers ample time to test key workflows. They could now also allocate time on Monday to test, instead of it being any part of the week.
Release calls were optional for minor releases because by definition nothing should be breaking.
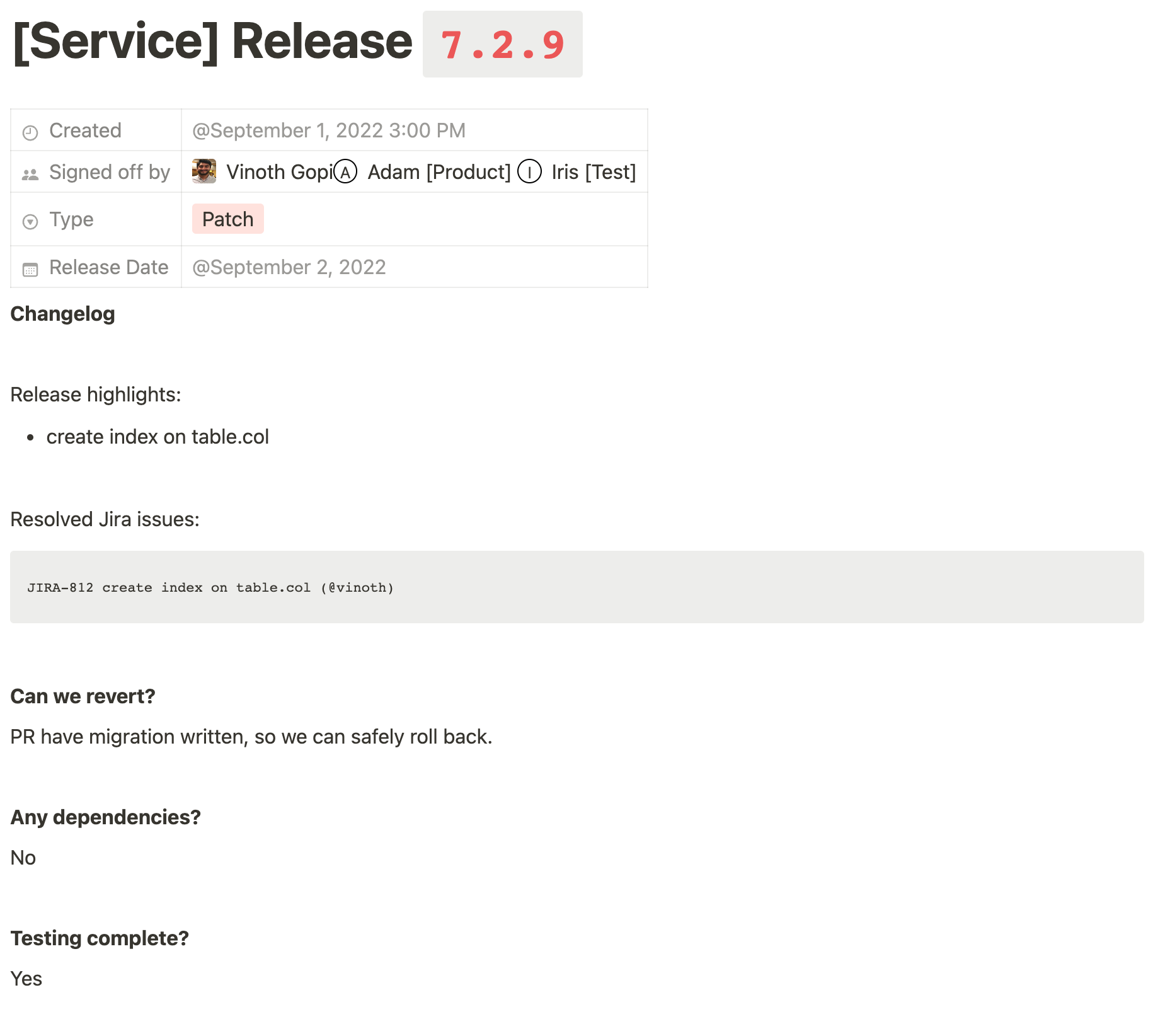
Checklist
Heavily inspired by the Checklist Manifesto, we put together a simple template doc that we ran through during every release call. It served two purposes:
- it had all the details about the release in a central place. If something goes wrong, we could immediately jump to this doc
- it is now a shared responsibility. No one person can be blamed for a production issue because multiple people would have signed off
What now?
Once these changes were implemented and the engineers got used to this new process, we got a lot more efficient. By slowing down the process to only 2 releases a week, we actually ended up being more deliberate in our releases, code quality improved and the release was better tested for functionality.
Now, if I see an alert on the #emergency channel, I first look at the date/time. If it was a Wednesday, I could just return to what I was doing before.